Python - Data science 資料科學 學習筆記 第1講 - IPython : 更好用的 Python
Python - Data science 資料科學 學習筆記 第1講 - IPython : 更好用的 Python
分享!這是我正在加強努力學習的 Python - Data science 資料科學 學習筆記 第1講。
為什麼選用 Python?
Python 成為第一流的科學計算工具,包括大型資料集的分析與視覺化,已經超過20年了。
這個發展也許會讓 Python 早期的支持者感到意外,因為 Python 在設計之初並沒有特別考慮到資料分析和科學計算。
把 Python 拿來運用在資料科學的理由來自於廣大且活躍的第三方套件生態系: NumPy 用來處理以同性質陣列為主的資料 ; Pandas 用來處理異質和標籤類型的資料; SciPy 用來進行一般的科學計算工作; Matplotlib 用來處理具有發行等級品質的視覺化; IPython 用來做為互動式的執行程式碼之共享;Scikit-Learn 可以進行機器學習。

IPython:更好用的 Python
IPython 被用來使用在 Python 有效率的進行交互式科學上,以及資料密集型的計算。從一些 IPython 在資料科學練習方面的功能開始,特別是在一些超越 Python 標準語法的部份。接著會再深入一些更好用的 「magic命令」,這些命令可以用來加速建立和使用資料科學的程式碼。最後將會提到一些 notebook 的特色,這些特色可以幫助我們更暸解資料,以及分享結果。
Shell 還是Notebook
第1講會討論到兩個主要的部份,分別是 IPython shell 和 Python notebook,大部份內容都和這兩者有關,而使用到的範例也會根據使用那一個比較方便而交替採用。先說明如何啟動 IPython shell 和 IPython notebook。








安装:
啟動 IPython Shell
可以在命令列輸入 ipython 啟動 Python 直譯器,或是透過像是 Anaconda 或是 EPD 這一類的發行套件,使用它們專屬的啟動程式。一旦啟動 IPython 之後,應該會看到如下所提示訊息:

啟動 Jupyter NoteBook
Jupiter notebook是 IPython shell 的瀏覽器圖形化介面版本。擁有許多動態的顯示能力。除了可以執行 Python / IPython 的陳述式。在 notebook 中還尤許使用者加入格式化的文字、靜
態或動態的視覺化資料、數學式子、JavaScript小部件(widge) 等等,這些文件也可以儲存起來,讓別人在他自己的系統中開啟並執行。
雖然 IPython notebook是在瀏覽器中檢視以及編輯,但它必須要連結到一個執行中的 Python 處理程序才有辦法執行程式碼,為了啟用這個處理程序 (就是所謂的「kernel」),需要在終端機中執行以下這個命令:
$ jupyter notebook

這行命令將會啟動一個讓瀏覽器可以瀏覽的本地端 web 伺服器,然後即刻顯示出一段像是下面這樣的記錄訊息:

在執行這行命令之後,預設的瀏覽器也會馬上被開啟,瀏覽目前本地端的 URL ,實際的網址視你的系統狀態而定。如果瀏覽器沒有順利地自動執行的話,也可以自行手動開啟瀏覽器程式,然後前往這個位址即可。(http://localhost:8888)
IPython 的求助與說明文件
當一個科技人被要求幫助遇到電腦相關問題的朋友、家人或是同事時,通常知道如何找到答案的情況,遠比可以直接回答的情況多。在資料科學也是一樣的。可以搜尋的網頁資源像是線上文件、郵件討論串、Stack Overflow網站的回答區均包含了相當豐富的資訊,甚至(特別是?)會找到之前你曾經搜尋過的主題。要成為一個資料科學家有效率的練習者,少去記憶一些每種可能情況下的指令和工具,多去學習如何有效率地從網頁搜尋引擎中找出未知的資訊。
IPython/Jupyter 最重要的功能之一就是縮短使用者和說明文件型式之間的距離,而且搜尋可以幫助我們更好效率地工作。儘管網頁搜尋可以回答複雜的問題。但在 IPython 中,其實就可以找到比想像還要多的資訊。如下所列的這些例子,在 IPython 中只要幾個按鍵就可以得到答案:


此符號可以使用在任何對象,包括物件的方法函式:

以及物件本身,也會依據不同的型態顯示出相對應的資訊:

重要的是,就算是針對自定義的函式以及物件也可以。以下定義了一個具有 docstring 的小型函式:

要替自定義的函式建立 docstring ,只要在第一行加上說明文用字串即可,因為 docstring 的內容通常都會有許多行,所以習慣上會使用 Python 的三引數字串符號。

透過 doctoring 方式取得說明文件的方法,也是讓你養成在編寫程或碼時,總是想到要加上行內說明文件習慣的一個好理由。
使用「??」取得原始程式碼
因為 Python 語言非常容易閱讀,通常可以藉由閱讀程式原始碼,進一步地對於感興趣的物件更深入地理解。 IPython 提供使用雙問號 (??)做為閱讀原始碼的快捷方法:

像是這樣簡單的函式,雙問號讓我們可以很快地看到隱藏在內部的細節。
但是如果多試幾次就會發現,有些時候在字尾附加上「??」並不會顯示出原始碼,通常這是因為你查詢的物件並不是使用 Python 實作的,而是 C 或是其他具編譯功能的語言所建立的。
此種情況下,「??」字尾的輸出結果會和「?」字尾是一樣的。你會發現,特別是那些 Python 內建物件和型態,例如前面例子中使用的 len:
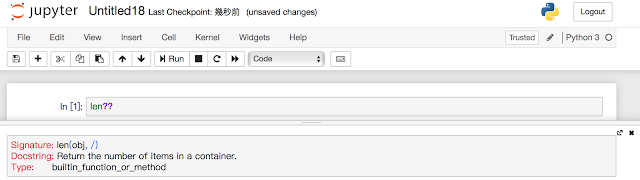
「?」以及「??」提供了一個快速的介面,讓我們可以找到任一 Python 函式或模組實際執行內容的相關資訊。
使用 Tab 補齊功能來探索模組
IPython 的另外一個好用的介面是 Tab 鍵自動補齊以及探索物件、模組、和名稱空間的功能。在接下來的例子中,將使用 <TAB>代表當 Tab 鍵被按下去的情況。
物件內容的 Tab 補齊
每一個 Python 物件都有許多的屬性和方法。就像之前說明過的 help 函式, Python 有一個內建的 dir 函式可以把這些屬性和方法都列出來,但是 Tab 自動補齊功能更好用,例如,想要瀏覽物件的所有可用屬性,可以在鍵入物件的名稱之後加上一個「 . 」句點符號,然後按下「Tab」按鍵。
只要輸入一個或多個字元,這個列表內容就會減少一些,此時再按下「TAB」按鍵就可以找到更符合的屬性或方法。
如果只剩一個符合的項目,按下「TAB」鍵就會直接把整列顯示出來。例如,以下的例子就會直接由 L.count取代。
雖然 Python 並沒有嚴格強制區分外部公有的和內部私有的屬性,但慣例上會使用底線符號來標明私有的內部屬性。為了避免混淆,這些私有的屬性和特殊的方法預設上在顯示時會被忽略,但是仍然可以透過加上底線的方式把它們顯示出來。
為了簡明一些,在這裡只列出實際輸出內容的前幾行。這些大部份都是 Python 的雙底線方法函式 (通常暱稱為「dunder」方法)。
在匯入套件的 Tab 補齊
Tab 補齊在匯入套件時也非常好用,例如,可以使用這個功能來找到 itertools 這個套件引入內容中,所有以 「co」開頭的方法:
In [10]: from itertools import co<TAB>
combinations compress
combinations_with_replaceent count
同樣的,也可以使用 TAB 補齊功能來檢視在你的系統中,可以匯入的套件有那些 (此功能和使用那一種第三方腳本,以及目前 Python 執行階段的能見度有關):
In [10]: import <TAB>
Display all 399 possibilities? (y or n)
Crypto dis py_compile
Cython distutils pyclbr
........... ............ ..........
diff lib pwd zmq
In [10]: import h<TAB>
hash lib mac http
heaps html hus1
(請留意,為了簡明顯示起見,在此不可能列出在我的系統中,所有 399 個可匯入的套件或模組。)
比 Tab 補齊更厲害的:萬用字元配對
在知道想要尋找的對象其開頭的幾個字元時,使用 Tab 補齊就非常方便,但是如果已知的字元是在函式或模組名稱的中間或是後面的話,這就派不上用場了。此時,IPython 提供的萬用字元「 * 」就可以用在這種情形上。
舉例來說,我們可以使用萬用字元來列出命令空間,所有以 「Warning」結尾的物件:

要留意的是 ,「 * 」可以符合任何的字串,也包括空字串。
同樣的,假設要找的是在名稱中的某處,包含某些字元的字串方法,可以使用以下方式:

在 IPython Shell 中的快速鍵
只要你花了一些時間在使用電腦,就會發現一些快捷鍵在工作流程中的用法。常用的像是 Cmd-C 和 Cmd-V (或是 Ctrl+C 和 Ctrl+V) 用來複製和貼上,就被廣泛的使用各式各樣的程式和系統中。老手們通常會更進一步:一些受歡迎的文字編輯器像是 Emacs、Vim 還有其他之類的,更是提供使用者各種複雜的快捷組合鍵。
IPython shell 沒有這麼誇張,但也提供了不少快捷鍵讓你在輸入指令時可以更快一些,這些快捷鍵其實不是 IPython 本提供的,而是透過相依的 GNU Readline 程式庫:因此,接下來有些列印的快速鍵可能會因為系統的配置而和你的有所不同。此外,這裡面有一些是運作在瀏覽器中的 notebook,這一節主要介紹的是在 IPython shell 使用的快捷鍵。
一旦你習慣使用快捷鍵,它們可以讓你快速的執行許多命令,你的手甚至可以不用離開鍵盤。如果你是 Emacs 的使用者,或是熟悉 Linux 型式的終端機操作,接下來的內容你將會非常熟悉。以下把這些快捷鍵分成幾組加以說明:導覽用快捷鍵、文字輸入快捷鍵、歷史命令快捷鍵以及雜項快捷鍵。
導覽用快速鍵
使用左方向鍵和右方向鍵在同一列中向前、向後移動非常直覺,但還是有其他的方法可以讓你的手不用離開你原先放的地方,而達到同樣的功能:
按鍵 動作
_________________________________________
Ctrl-a 把游標移至本列的最開頭位置
Ctrl-e 把游標移至本列的最末尾位置
Ctrl-b (或是左方向鍵) 把游標後退 (向左) 一個字元
Ctrl-f (或是右方向鍵) 把游標前進 (向右) 一個字元
文字輸入快捷鍵
大家習慣使用倒退鍵來刪除前一個字元,但手指頭還是要多移動一些距離才會到達這個按鍵,且它一次只能刪除一個字元。 在 IPython,有許多快捷鍵可以指定刪除輸入的文字內容的某些部份,其中最有用的就是一次刪除整列文字的快捷鍵。你很快會習慣使用 Ctrl-b 和 Ctrl-d 來取代原本你使用的倒退鍵刪除字元。
按鍵 動作
_________________________________________
倒退鍵 刪除本列的前一個字元
Ctrl-d 刪除本列的下一個字元
Ctrl-k 把從游標所在位置到本列末尾的所有文字剪下來
Ctrl-u 把從游標所在位置到本列開頭的所有文字剪下來
Ctrl-y 把之前剪下的內容貼上
Ctrl-t 交換前面2個字元
歷史命令快捷鍵
也許最好用的,應該是在這裡要說明的,用來操作在 IPython 中輸入過的歷史命令。在 IPython 使用的命令列歷史資訊可以跨越不同的操作階段,因為它把曾經輸入過的命令都儲存在 IPython profile 目錄的 SQLite 資料庫裡頭。最直覺的方式就是使用上、下方向鍵在這個歷史命令區中找出想要使用的命令,當然也有其他的選擇:
按鍵 動作
_________________________________________
Ctrl-p (或上方向鍵) 往前取得一個曾經輸入過的命令
Ctrl-n (或下方向鍵) 往後取得一個曾經輸入過的命令
Ctrl 反向搜尋曾經輸入過的歷史命令
反向搜尋特別有用。回想在人一節中,我們定義一個叫做 square 的函式,請從一個新的 IPython shell 執行階段透過反向搜尋再一次找出這個定義。當按下 Ctrl-r 時,可以看到如下所示的提示:
In [1]:
(reverse-i-search)'':
在此時如果開始輸入一些字元, IPython 將會自動以最近使用過的命令填入,然後顯示出符合那些字元的歷史命令:
In [1]:
(reverse-i-search)'sqa' ' : square??
在任何時候都可以輸入更多字元改善搜尋的結果,或是再次按下「 Ctrl-r 」更進一步搜尋其他符合的歷史命令。延續前面的操作,再按二下「 Ctrl-r 」,則會出現如下所示的樣子:
In [1]:
(reverse-i-search)'sqa': def square(a):
"""Return the square of a"""
return a ** 2
一旦找到想要的命令,接下 Return (或是 Enter) 就是可以終止此次的搜尋。接著使用這個找到的命令,繼續往下操作:
In [1]: def square(a):
"""Return the square of a"""
return a ** 2
In [2]: square(2)
Out [2]: 4
你也可以使用 「Ctrl-p / Ctrl-r 」或是上、下方向鍵在歷史命令中搜尋那些符合開頭字元的歷史命令,也就是說,如果輸入 「 def 」然後按下 「 Ctrl-p 」,就只會找到那些曾經輸入過,而且是以 「 def 」開頭的命令。
雜項快捷鍵
最後,一些不好歸類在上述的分類中,但也是很有用的快捷鍵如下:
按鍵 動作
_________________________________________
Ctrl-l 清除終端機畫面
Ctrl-c 中斷目前的 Python 命令
Ctrl-d 結束離開 IPython
「 Ctrl-c 」快捷鍵特別是在不小心執行了一個要運算很久的工作時非常有用。
IPython 的 Magic 命令
在前二節中展示了 IPython 能夠讓我們更有效的以互動的方式使用與探索 Python。在此將開始探討一些 IPython 架構在 Python 之上加強的語法。
IPython 在標準的 Python 語法之上加了一些命令,這些以 「 % 」字元開頭的,就是大家所熟悉的 magic command (神奇命令,或魔術命令)。這些 magic 命令被設計用來更簡潔的解決在標準資料分析時常見的一些問題。 magic 命令主要分成兩種型式:以 「 % 」開頭,用來操作單行輸入的 line magic,以及以 「 % 」開頭,用來操作多行輸入的 cell magic 。在此將會展示和討論一些簡要的例子。
貼上程式碼區塊:%paste 和 %cpaste
當在使用 IPython 解譯器時,當貼上多行的程式區塊時,經常會遇到一些預期之外的錯誤,尤其是其中含有縮排和解譯器記號的時候。一個常見的例子是,當你從網頁中找到一些範例程式,而想要把它們貼到解譯器裡面時。請看以下這個簡單函式:
>>> def donothing (x):
..... return x
這段程式被格式化成可以放在 Python 的解譯器中,但是如果你把它們直接貼到 IPython 中,則會出現以下的錯誤:
In [2]: >>> def donothing (x):
....: ..... return x
....:
File "<ipython-input-20-5a66c8964687>", line 2
... return x
^
SyntaxError: invalid syntax
直接貼上時,解譯器對於那些命令提示字元感到困惑,但別擔心,IPython 的 「 %paste 」magic 命令就被設計用來處理這種型式的多行程式碼輸入:
In [3]: %paste
>>> def donothing(x)
..... return x
### -- End pasted text --
「 %paste 」命令兼輸入和執行程式碼,所以現在這個函式已經準備好可以被呼叫使用了:
In [4]: donothing(10)
out [4]: 10
類似的命令是 「 %paste 」,它並不直接貼上,而是開啟一個交談式的多行輸入介面讓的們可以自行貼上一行或是多行指令片段,並批次執行之:
In [5]: %paste
Pasting code; enter '--' alone on the line to stop or use Ctrl-D.
:>>> def donothing(x)
:...... return x
:--
這些 magic 命令,包括接下來會看到的,讓一些在 Python 標準直譯器中做不到的功能可以在 IPython 中實現。
執行外部程式碼:%run
當開始撰寫更多程式碼時,你會想要同時可以在 IPython 中以互動的方式探索程式,以及使用編輯器來儲存,可以重複使用的程式碼。與其開啟另外一個新視窗來執行外部程式碼,在同一個 IPython 階段中執行的這些程式碼更方便,使用「 %run 」命令就可以做到這一點。舉個例子,假設建立了一個 myscript.py 檔案,其內容如下:

可以透過以下的方式在 IPython 中執行:
In [6]:%run mysciprt.py
1 square is 1
2 square is 4
3 square is 9
在執行了這段程式之後,其中定義的函式現在於 IPython 階段中已是可用的了:
In [7]:square(5)
Out [7]: 25
在 IPython 直譯器中使用「 %run 」執行程式有幾個可以調校如何執行程式碼的選項,可藉由鍵入 %run 以取得說明文件。
計算程式碼執行時間: %timeit
另外一個有用的 magic 命令是 「 %timeit 」,這是用來自動化測量緊隨在後的那個單行 Python 敘述執行時間的命令。例如,如果想要檢查 list comprehension 的效能:

%timeit 的優點是它可以針對簡短的命令,自動化的執行許多次以求出更令人信服的結果。對於多行的敘述,再加上一個「 % 」符號就可以改成為處理 cell 的命令,用來處理多行的輸入。例如,以下是使用 for 迴圈的一個等效串列建構式:

馬上可以看出,在這個例子中,使用 list compregension 比使用 for 迴圈建構串列還要快上 10%。
Magic 函式的求助:?、 %magic,以及 %lsmagic
就像是其他一般的 Python 函式,IPython 的 magic 函式也有 docstring,這份好用的說明文件可以透過標準的方式來取得,例如,要讓取 %timeit magic 命令的說明文件,只要簡單的輸入:

其他函式說明文件,也是使用相同的方式,而要取得對於 magic 函式的一般性介紹,包括一些使用範例,可以輸入如下:

要很快的顯示出所有,可以使用的 magic 函式清單,只要輸入如下:

最後,還是要提到,有需要的話,你也是可以使用相當直覺的方式定義,一個自己的 magic 函式。
輸入和輸出的歷程
之前提到過,在 IPython shell 中可以使用上方向鍵,以及下方向鍵,或是使用 Ctrl-p / Ctrl-n 快捷鍵找出之前輸入過的命令。更進一步的,包括在 shell 以及 notebook,IPython 有許多方式可以取得之前輸入過的命令所產生之輸出,包括這些命令本身的字串版本,接著來探討這個部份。
IPython 的 In 和 Out 物件
行文到此,相信你已經相當熟悉在 IPython 中使用 In [1]:/out [1]: 此種型式的提示字元。但是,這些其實不只是為了好看而已,它們提供了一些線索,讓我們可以在目前的執行階段中,存取之前的輸入和輸出。假設開始了一個執行階段,看起來像是以下這個樣子:

上述程式碼匯入了 math 套件,然後計算數字 2 的 SIN 和 COS。這些輸入和輸出都被顯示在 shell 中,並標上 In/Out 標籤,但不只如此,事實上,IPython 建立了一些名為 In 和 Out 的 Python 變數,並自動更新以反映,這些歷程資訊:

In 物件是一個串列,它依序保存了所有輸入的內容 (串列中的第一個項目,就是一開始的地方,因此 In [1] 就是第一個命令):

Out 並不是一個串列,而是一個字典,它由輸出竹所對應到的輸入編號做為索引:

並不是所有的操作都會有輸出:例如,import 敘述和 print 敘述並不會影響輸出。也許你會好奇為什麼 print 不會有輸出,如果把它看成是一個函式的話就可以理解,因為此函式的傳回值是 None ,為了精簡起見,所有回傳值是 None 的命令並不會被加到 Out 中。
此時,當需要和之前的執行結果交互使用時非常好用。例如,要使用之前 sin(2) ** 2 和 cos(2) ** 2 的執行結果來進行加總,如下:
In [8]: Out[2] ** 2 + Out[3] ** 2
Out [8]: 1.0
如預期的,三角恆等式的結果為 1.0 。在這個例子中使用之前的結果,也許並不是那麼必要,但是如果你之前執行過一個非常佔計算時間的結果,就會非常需要重用該結果以避免,重新再花大量時間去執行它。
底線快捷符號和先前的輸出
標準的 Python shell 只包含一個簡單的快捷符號用來處理之前的輸出:這個變數 「 _ 」(也就是一個單一的底線) 用來一直保持著,最近的一之輸出,而是這個功能在 IPython 也可以使用:
In [9]: print(_)
1.0
但 IPython 更進一步,可以使用雙底線,去取得兩次之前的輸出,三個底線符號,則可以再往前一步 (會跳過所有沒有輸出的命令):
In [10]: print(_)
-0.4161468365471424
In [11]: print(_)
0.9092974268256817
IPython 就停留在三個底線符號,因為再多就不好數了,而且超過3個之前的結果,使用行號來取得輸出,還比較容易。
還有一個快捷符號,也是要提一下,那就是把標準的 Out[X] 改為 _X (也就是一個底線再加上一個代表行號的數字):
In [12]: Out[2]
Out [12]: 0.9092974268256817
In [13]: _2
Out [13]: 0.9092974268256817
抑制輸出
有時候你希望讓敘述不要輸出。或是有時候執行的結果不想要放在輸出的歷程中,亦或是要讓它在別的參考被移除時可以解除配置。最簡單抑制命令之輸出的方法,是在該命令的行末處加上一個分號:
In [14]: math.sin(2) + match.cos上(2);
這個敘述會被安靜的計算,而結果不會被顯示在螢幕上,也不會被儲存在 out 這個字典變數中:
In [15]: 14 in out
Out [15]: False
相關的 Magic 命令
%history magic 命令可以用來批次存取之前用過的輸入。底下是一次列出前面 4 個輸入的方法:

就像之前一樣,可以輸入 %history? 取得更多的資訊以及可用的選項說明。其他類似的 magic 命令包括 %erun (可以用來重新執行歷史命令的某一部份)以及 %save (用來把某一群歷史命令存成檔案)。
IPython 和 Shell 命令
當以交談式使用標準的 Python 直譯器時,其中一個令人挫折的地方是,你會面對需要在多個視窗之間來回切換,以便執行 Python 工具和系統命令列工具的情況。IPython 彌補了這個缺口,它提供一些語法,可以直接在 IPython 的終端機中執行作業系統的 shell 命令。神奇的地方在於「驚嘆號」:所有放在「 ! 」之後的任何內容都不會在 Python 核心中執行,而是放到作業系統命令列上去執行。
接下來的操作環境,假設是在 Unix-like 作業系統中,像是 Linux 或是 Mac OS X 執行。其中一些操作示例在 Windows 作業系統下將會無法順利執行,因為 Windows 使用不同的 shell 型態 (然而隨著 Windows 下的原生 Bash 在 2016年發佈,很快的這將不會是問題!) 如果不熟悉作業系統 shell 命令操作,建議你可以複習一下由 Software Carpentry Foundation 所整理的 shell 教學 (http://swcarpentry.github.io/shell-novice/)。
Shell 的快速介紹
Shell 是一個文字的方式和電腦互動的方法。早在 1980年中期,當 Microsoft 和 Apple 推出,他們像現在一樣無所不在圖形式作業系統之後,大部份的電腦使用者和他們的作業系統互動的方式,就是使用滑鼠點按選單以及拖放移動的操作。但是作業系統在圖形使用者介面之前,就存在著使用文字輸入的基本控制方式:也就是在提示字元之後,使用者藉由輸入一個命令,然後電腦依照使用者教它的方式去運行。這些早期的提示字元系統,就是這些 shell 和終端機的前導者,也是現代資料科學家們現在還在使用的方式。
不熟悉 shell 的人也許會問,透過在圖示及選單上簡單的點按就可以完成許多結果時,為什麼還要這麼麻煩?Shell 的使用者也許會用另一個問題回答:透過輸入文字就可以完成這樣多工作時,為什麼還要用滑鼠去找圖示或選單來點按?這聽起來只是典型的在技術偏好上的抉擇,但是如果面對的工作沒那麼簡單時,就可以較清楚的看出,處進階工作時 shell 提供更多的控制,雖然它的學習曲線會讓一般電腦程度的使用者感到害怕。
舉例來說,這裡有一個 Linux / OS X shell 階段的例子,當使用者要在他的系統查詢、建立、以及修改目錄和檔案時 (osx:~ $ 是命令提示字元,所有在 $ 號後面是要輸入的命令;放在 # 後面的文字表示,這是一個註解的描述,並不是要輸入的內容):

# echo 就像是 Python 的 print 函式
# pwd = 印出工作的路徑 這就是我們所在的 「 path 」
# ls = 列出工作中目錄的內容
# cd = 變更目錄
這些動作都只是一些熟悉的操作之精簡方式 (瀏覽目錄結構、建立一個目錄、搬移一個檔案等等),它使用輸入文字取代透過滑鼠在圖示和選單之間的點按動作。只需要少數的命令 (pwd、ls、cd、mkdir、還有 cp ) 就可以進行大部份的檔案操作。當你從基礎再進一步往前時, shell 操作方法有時候,會更好用。
IPython 中的 shell 命令
你可以在 IPython 的 shell 環境中執行作業系統,任何命令提示字元接受的命令,只要在該指令前加上 「 ! 」就可以了。例如:ls、pwd、和 echo 這些命令,如下所示:

取出 / 傳入值到 shell
shell 命令並不只是可以從 IPython 中呼叫執行,也可以在 IPython 的名稱空間中和程式碼互動。例如,可以使用等號把任何 shell 命令中執行後的輸出放在 Python 的串列中:
傳回的值,並不是以標準竹戈串列型態回傳,面是由 IPython 所定義的一個特別的 shell 傳回值型態:

它的行為看起來像是 Python 串列,但是它具有更多的功能,像是可以使用 grep 和 fields 方法,以及 s、n、和 p 等屬性,讓我們更容易搜尋、過慮、和顯示這些結果。更多的相關資訊可以使用 IPython 內建的求助功能取得。
反過來,如果要傳遞 Python 的變數到命令列的執行環境中,可以透過 {varname} 語法:

大括號中的內容即為變數名稱,它會被 shell 命令列中的變數所取代。
和 Shell 相關的 Magic 命令
在使用 IPython 命令一段時間之後,你可能會注意到沒有辦法使月手 !cd 在檔案系統中切換:

這是因為在 notebook 中的 shell 命令是被執行在一個暫存的子 shell 中的關係。如果你打算永久的切換,目前的工作目錄,可以使用 %cd 這個 magic 命令:
實際上,在預設的情況下,其實可以不需要使用 % 符號:

這就是所謂的 automagic 函式,這樣的行為,可以透過 %automagic 這個函式來切換。
除了 %cd ,其他可以用的和 shell 相關的 magic 函式包括 %cat、%cp、%env、%man、%mkdir、%mv、%rm、以及 %rmdir,在 automagic 處於 on 的情況下,這些命令都是不需要加上 % 就可以使用的,這樣的功能,讓我們在 IPython 中操作時,就好像是在作業系統的命令提示字元 (終端機) 下一樣:

像是這樣對於 shell 指令的操作方式,就如同在終端機視窗一樣,就可以讓我們在撰寫程式碼時,減少在直譯器和 shell 命令之間來回切換的次數。
錯誤以及除錯
程式的開發以及資料的分析,總是需要許多反覆的測試。而 IPython 就提供了一些工具,讓這個過程更加順手。將會簡要的函蓋控制 Python 例外回報的一些選項,然後探索這些用來在程式碼中除錯的工具。
控制例外
當 Python 腳本執失敗時,通常都會產生一個例外。當直譯器遇到這些例外時,這些造成錯誤的相關資訊,會被放在 trackback 中,它可以在 Python 中加以存取。透過 %xmode 這個 magic 函式, IPython 允許控制。當例外產生時,要顯示資訊的數量。參考以下這段程式碼:

呼叫 func2 造成錯誤,而檢視列出來的追蹤資訊,讓我們可以明確的,看出發生了什麼事,在預設的情況下,這樣的追蹤包含了可以指向,導致這個錯誤的步驟之多行前後文內容。 %xmode magic 函式 (簡稱為例外模式) 用來改變列印資訊的模式。
%xmode 需要輸入一個參數,也就是模式設定,共有三種模式可用:Plain、Context,和 Verbose。預設是 Context,這個模式就是上面看起來的樣子,而 Plain 模式則較為精簡。呈現的資訊較少:
 1
1
Verbose 模式加上了一些額外的資訊,包括任何被呼叫的函式所使用之參數:

這些額外的資訊可以協助我們更明確的暸解,發生這個例外的原因。所以,為何不全部使用 Verbose 模式? 因為當程式碼很複雜時,這樣的回溯會變得非常長。依照不同的內文而定,有時候預設的簡要模式會比較容易使用。
在檢視回溯訊息不夠用時的除錯方法
Python 標準的互動式除錯是 pdb。它讓使用者可以進入程式碼,逐列去理解不易發現的引發錯誤之原因,而 IPython 的加強版是 ipdb,也就是 IPython 的除錯器。
在 IPython 中,最方便的除錯介面是 %debug magic 命令。在遇到例外之後呼叫它,它會自動的開啟一個交談式的介面並提示出現例外的點。 ipdb 提票字元讓我們可以探索目前堆疊中的狀態,查看可用變數,甚至執行 Python 的命令。
來看看最近遇到的例外,然後做些基本的工作 (列印出 a 和 b 的值),之後輸入 quit 離開除錯階段:

然而,這個交談式的除錯器,允許我們做更多的事,甚至可以在記憶體堆疊中上下探查,並查詢其中變數的值:

這樣可以快速的找出不只是引發錯誤的地方,也可以知道是那些函式的呼叫,引發了這次的錯誤。
如果想要讓除錯器,在發生例外時自動的執行,可以使用 %pdb magic 函式去開啟,這樣的自動行為:

最後,如果打算讓一後程式碼,從頭到尾都是以互動的方式執行,可以使用 %run -d ,接著使用 next 命令一步一步的執行,每一行程式碼。
除錯命令的部份列表
交談式的除錯介面中,還有許多命令可以使用,在此只列出其中的一部份。底下表格中所列的是一些常用的命令,以及其說明:
命令 說明
_________________________________________
list 顯示在檔案中目前的位置
h(elp) 顯示所有命令的列表,或是針對指定的命令提供求助訊息
q(uit) 離開除錯器及程式
c(ontinue) 離開除錯器,但是程式還是繼續執行
n(ext) 前往程式的下一步
<enter> 重複前一個命令
p(rint) 印出變數
s(tep) 進入副程式中
r(eturn) 離開程式
剖析和測定程式碼的時間
在開發程式的過程,以及建立資料處理管線 (popeline) 時,經常有一些需要在不同的實作方式間取捨的情況。過早在開發,你的演算法時關心這個問題,可能會適得其反。就像是 Donald Knuth 說的「 在百分之九十七的時間裡,我們應該要忘記,那些小的效能問題。太早優化是萬惡之源 」。
但是當程式碼已經可以運作時,更進一步的去挖掘,它的效能就很有用了。有時候探查一個命令或是一組命令的執行時間很有用處,其他時候,深入挖掘多行的處理程序,然後判定在一些複雜的一系列操作中,那裡是瓶頸也很有用。 IPython 提供了各式各樣的功能,用來操作,這一類型的剖析和測時。在此時將要推論以下的 IPython magic 命令:
%time 單一行敘述的執行時間
%timeit 重複執行單一行敘述以取得更正確的時間
%prun 使用剖析器執行程式碼
%lprun 使用逐行執行剖析器執行往式碼
%memit 測量單一行敘述的記憶體使用量
%mprun 使用逐行執行記憶體剖析器執行程式碼
後面4個命令,並不在 IPython 的預裝套件中,需要安裝 line_profiler 和 memory_profiler 延伸套件才行。
程式碼片段的測時:%timeit 和 %time
在 「 IPython 的 Magic 命令 」中曾看到過 %timeit line magic 和 %%timeit cell magic 被用來測量重複執行的程式碼片段之時間:

因為此運算執行的非常快,所以 %timeit 自動做了非常大量的重複運算。對於那些執行較慢的命令, %timeit 會自動調整,使用較少的重複次數:

有時候重複運算,並不是最好的選項。例如,當排序一個串列時,可能會被重複的運算所誤導。對有序串列的排序速度,比對末排序的串列進行排序的速度要來得快,因此重複這些運算會造成測時上的誤差:

像這種情形,%time 可能會是比較好的選擇,對於需要長時間執行的命令也是,此種命令較不會受到一些短的系統相關延遲所影響。以下是比較對於已排過序以及末排過序的串列,進行排序運算的時間長度:

請留意有序的串列排序運算快了多少,以及使用 %time 測到的時間比使用 %timeit 測到的時間多了多少,就算是對有序的串列也一樣,事實上,%timeit 在私底下做了一些聰明的事,以防止系統呼叫妨礙計時工作。例如,它預防了系統對末使用的 Python 物件進行清除的工作 (也就是記憶體垃圾回收),這有可能會影響到計時。也因為這個原因,%timeit 的結果通常會明顯的比 %time 還好。
使用 %% 的 cell magic 語法可以讓 %time 像 %timeit 一樣,對多行的程式碼,進行測量時間的工作:

更多關於 %time 和 %%timeit 的資訊,以及可用的選項,請使用 IPython 的求助功能 (也就是在 IPython 的提示字元後輸入 %time?)
剖析整個程式: %prun
一個程式是由許多單行的敘述所構成,有時候在前後文中去量測時間,會比只量測個別的敘述來得重要。 Python 有內建程式碼剖析器 (請參考 Pytho 的說明文件),但 IPython 提供一個更方便的方法,使用這個剖析器,就是利用 %prun 這個 magic 函式。
舉例來說,以下定義了一個進行一些計算的簡單函式:

現在以 %prun 帶著一個函式呼叫來看看剖析後看結果:

在 notebook 中輸出被顯示成像是下面這樣的頁面調度程序:

結果之表格以,每一個函式呼叫的總時間排序列表,花越多時間的放在越上面。在此例中,最多的執行時間是在 sum_of_lists 中的列表式推導 (list comprehension)。從此點,我們可以開始思考,要改進演算法的效能時,需要做什麼樣的改變。
使用 %lprun 逐行剖析
使用 %lprun 以函式為單位來剖析程式很有用,但有時候如果能有逐行的剖析報告會更加的方便。這個功能並沒有內建在 Python 和 IPython 中,需要安裝 line_profiler 套件才行。安裝 line_profiler 這個套件,只要使用 Python 的套件管理器 pip 就可以了:
$ pip install line_profiler
接下來,使用 IPython 載入 line_profiler 提供給 IPython 的延伸模組:

現在,%lprun 命令將可以對任何一個函式執行逐行剖析。在此例中,需要明確的指定要剖析的是那一個函式:

和之前一樣,此 notebook 會發送,這個結果到頁面調度程序,看起來會像是下面這個樣子:

最頂端的這些資訊,透露出閱讀這些結果的關鍵:計時的時間,以微秒為單位,從這裡可以看出程式中,那裡花掉了最多的時間。根據此點,可以利用這些資訊去修改程式,讓它在需求的使用情境下,得到更好的執行效能。
剖析記憶體的使用:%memit 和 %mprun
另一個面向的剖析是在運作時,記憶體使用的總量,這可以使用,另外一個 IPython 的延伸套件:memory_profiler 做到。就像是 line_profiler,也是使用 pip 來安裝,這個延伸套件:
pip install memory_profiler
然後在 IPython 中載入這個延伸模組:

此記憶體剖析延伸模組,包含了2個有用的 magic 函數:%memit magic (提供風同於 %timeit 的記憶體量測) 以及 %mprun 函式 (等同於 %lprun 的記憶體量測)。 %memit 函式使用起來相對簡單:

由上可以看出,這個函式大約使用了 100 MB的記憶體。
對於逐行列出記憶體的使用,可以使用 %mprun magic 。不幸的是,這個的指令,只能使用在分開定義的外部模組,不能使用在 notebook 裡面的。所以,接下來我們要透過 %%file magic 建立一個簡單的模組叫做 mprun_demo.py,在裡面放入加了一點改變的sum_of_lists 函式,讓記憶體的剖析結果,可以更清晰一些:

現在可以匯入這個新版本的函式,然後透過記憶體逐行剖析器來執竹:

結果也是以頁面調度器的方式呈現,提供了此函式記憶體的使用情形,看起來像是以下這個樣子:

其中在 Increment 欄位可以看出,每一行所影響的總記憶體有多少:可以觀察當建立和刪除串列 L 時,多使用了25 MB 的記憶體,這是送在 Python 直譯器本身的背景記憶體用之上的。
分享!這是我正在加強努力學習的 Python - Data science 資料科學 學習筆記 第1講。
為什麼選用 Python?
Python 成為第一流的科學計算工具,包括大型資料集的分析與視覺化,已經超過20年了。
這個發展也許會讓 Python 早期的支持者感到意外,因為 Python 在設計之初並沒有特別考慮到資料分析和科學計算。
把 Python 拿來運用在資料科學的理由來自於廣大且活躍的第三方套件生態系: NumPy 用來處理以同性質陣列為主的資料 ; Pandas 用來處理異質和標籤類型的資料; SciPy 用來進行一般的科學計算工作; Matplotlib 用來處理具有發行等級品質的視覺化; IPython 用來做為互動式的執行程式碼之共享;Scikit-Learn 可以進行機器學習。

IPython:更好用的 Python
IPython 被用來使用在 Python 有效率的進行交互式科學上,以及資料密集型的計算。從一些 IPython 在資料科學練習方面的功能開始,特別是在一些超越 Python 標準語法的部份。接著會再深入一些更好用的 「magic命令」,這些命令可以用來加速建立和使用資料科學的程式碼。最後將會提到一些 notebook 的特色,這些特色可以幫助我們更暸解資料,以及分享結果。
Shell 還是Notebook
第1講會討論到兩個主要的部份,分別是 IPython shell 和 Python notebook,大部份內容都和這兩者有關,而使用到的範例也會根據使用那一個比較方便而交替採用。先說明如何啟動 IPython shell 和 IPython notebook。
Windows 安裝Python
請到 Python的官方網站下載python,版本記得選取 3.6.x。
Python 官網:https://www.python.org

勾選 Install Now 然後一直下一步
記得「Add Python 3.6 to PATH」一定要勾起來
記得「Add Python 3.6 to PATH」一定要勾起來

確認
安裝完之後,在terminal(Mac or Linux)或是在cmd(Windows)再輸入一次

安裝Jupyter



沒有的話,到這裡下載吧~
安裝jupyter

開始使用

Mac下安装pip,virtualenv,IPython
1. pip Python有兩個著名的包管理工具easy_install.py和pip。在Python2.7的安装包中,easy_install.py是默認安装的,而pip需要我们手動安装。
安装:sudo easy_install pip
pip 安装别的模塊:pip install module_name
2. virtualenv
virtualenv 是一個創建python隔離環境的工具,可以解决python包的依赖問題, 版本問题和權限問題。
安装:sudo pip install virtualenv
基本用法(創建一個環境):virtualenv ENV
激活:. ENV/bin/activate
離開這個環境:deactivate
删除環境
如果要删除虚擬環境,只需退出虚擬環境後,删除對應的虚擬環境目錄即可。
如果要删除虚擬環境,只需退出虚擬環境後,删除對應的虚擬環境目錄即可。
查詢帮助:virtualenv -h
3. IPython IPython是一種基於Python的交互式解釋器。相較於原生的Python Shell,IPython提供了更為强大的编輯和交互功能,增强的Python Shell。
官方安装教程:點擊此處。 使用官方教程可能出現如下問題:
Found existing installation: setuptools 1.1.6 Uninstalling setuptools-1.1.6:
这是因為新版本的osx默認自動開啟了SIP(System Intergrity Protection),導致就算使用sudo也無法修改一些文件。較好的解决辦法就是安装在user權限下,使用如下命令:
pip install --user IPython
這是比較優雅的做法,還有一種辦法就是安装之前關掉SIP。
重啟系统,在開機聲音響起的同時按住 Command + R 鍵,當出現蘋果 Logo 黑白畫面的时候鬆開键盤,進入恢復模式的操作面板,然後打開「终端機」,輸入:
csrutil disable
然後重啟,這樣就關掉了SIP。
如何啟動 IPython?
如果你發現,鍵入 IPython 無法啟動,使用如下命令:
如何啟動 IPython?
如果你發現,鍵入 IPython 無法啟動,使用如下命令:
python -m IPython
可以在命令列輸入 ipython 啟動 Python 直譯器,或是透過像是 Anaconda 或是 EPD 這一類的發行套件,使用它們專屬的啟動程式。一旦啟動 IPython 之後,應該會看到如下所提示訊息:

啟動 Jupyter NoteBook
Jupiter notebook是 IPython shell 的瀏覽器圖形化介面版本。擁有許多動態的顯示能力。除了可以執行 Python / IPython 的陳述式。在 notebook 中還尤許使用者加入格式化的文字、靜
態或動態的視覺化資料、數學式子、JavaScript小部件(widge) 等等,這些文件也可以儲存起來,讓別人在他自己的系統中開啟並執行。
雖然 IPython notebook是在瀏覽器中檢視以及編輯,但它必須要連結到一個執行中的 Python 處理程序才有辦法執行程式碼,為了啟用這個處理程序 (就是所謂的「kernel」),需要在終端機中執行以下這個命令:
$ jupyter notebook

這行命令將會啟動一個讓瀏覽器可以瀏覽的本地端 web 伺服器,然後即刻顯示出一段像是下面這樣的記錄訊息:

在執行這行命令之後,預設的瀏覽器也會馬上被開啟,瀏覽目前本地端的 URL ,實際的網址視你的系統狀態而定。如果瀏覽器沒有順利地自動執行的話,也可以自行手動開啟瀏覽器程式,然後前往這個位址即可。(http://localhost:8888)
IPython 的求助與說明文件
當一個科技人被要求幫助遇到電腦相關問題的朋友、家人或是同事時,通常知道如何找到答案的情況,遠比可以直接回答的情況多。在資料科學也是一樣的。可以搜尋的網頁資源像是線上文件、郵件討論串、Stack Overflow網站的回答區均包含了相當豐富的資訊,甚至(特別是?)會找到之前你曾經搜尋過的主題。要成為一個資料科學家有效率的練習者,少去記憶一些每種可能情況下的指令和工具,多去學習如何有效率地從網頁搜尋引擎中找出未知的資訊。
IPython/Jupyter 最重要的功能之一就是縮短使用者和說明文件型式之間的距離,而且搜尋可以幫助我們更好效率地工作。儘管網頁搜尋可以回答複雜的問題。但在 IPython 中,其實就可以找到比想像還要多的資訊。如下所列的這些例子,在 IPython 中只要幾個按鍵就可以得到答案:
- 如何呼叫某個函式?這個函式有什麼參數以及選項?
- 某個 Python 物件的原始碼是什麼?
- 匯入了什麼套件?這個物件的屬性和方法函式分別是什麼?
使用「?」取得說明文件
Python語言和它的資料科學生態系是以主體而建立的,而存取說明文件是其中一個重要的功能。每一個 Python 的物件都包含了一個被稱為是 docstring (文件字串)字串的參考。在大部份的情況下, docstring 會包含有對此物件的內容、以及使用方法的精簡摘要。Python有一個內建的 help( ) 函式可以用來存取這些資訊並把它們顯示出來。例如,要檢視內建的 len 函式之說明文件,可以操作如下:

在不同的解譯器中,求助訊息可能會以行內文件的方式,或是以獨立突現式視窗來顯示。
因為經常會對 Python 物件進行求助查詢,所以 IPython 提供「?」字元做為取得這些說明文件幾及相關資訊的快捷方式,如下所示:
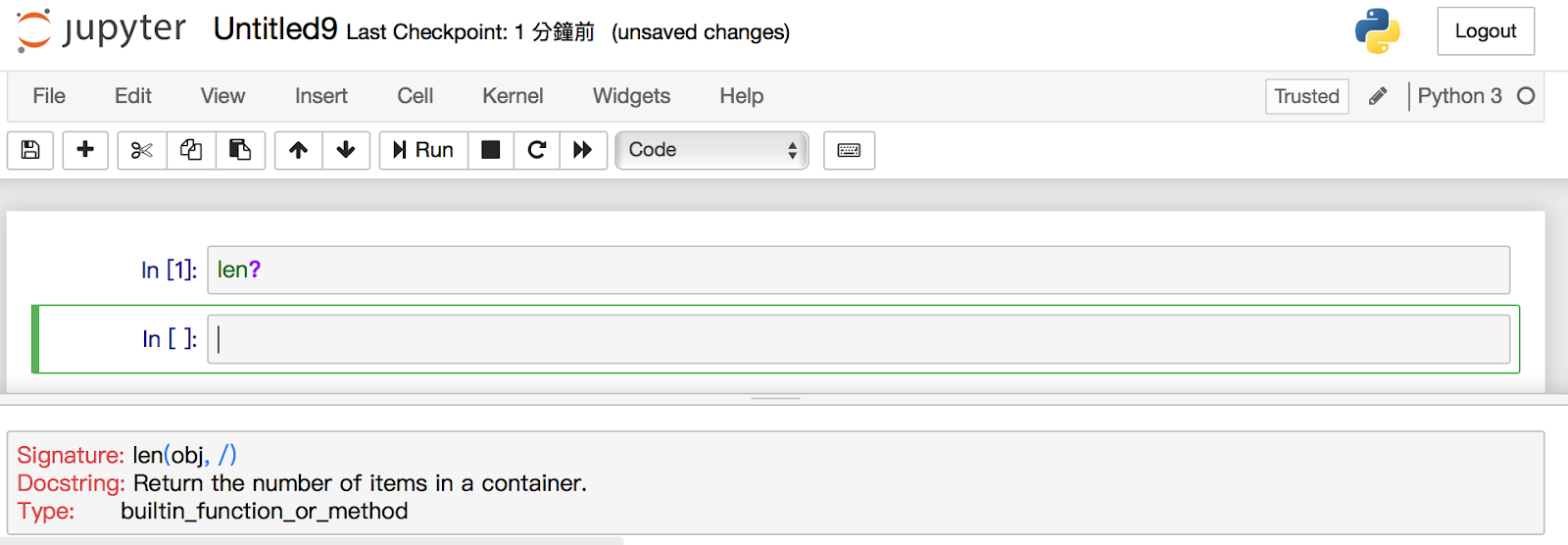
此符號可以使用在任何對象,包括物件的方法函式:

以及物件本身,也會依據不同的型態顯示出相對應的資訊:

重要的是,就算是針對自定義的函式以及物件也可以。以下定義了一個具有 docstring 的小型函式:

要替自定義的函式建立 docstring ,只要在第一行加上說明文用字串即可,因為 docstring 的內容通常都會有許多行,所以習慣上會使用 Python 的三引數字串符號。

透過 doctoring 方式取得說明文件的方法,也是讓你養成在編寫程或碼時,總是想到要加上行內說明文件習慣的一個好理由。
使用「??」取得原始程式碼
因為 Python 語言非常容易閱讀,通常可以藉由閱讀程式原始碼,進一步地對於感興趣的物件更深入地理解。 IPython 提供使用雙問號 (??)做為閱讀原始碼的快捷方法:

像是這樣簡單的函式,雙問號讓我們可以很快地看到隱藏在內部的細節。
但是如果多試幾次就會發現,有些時候在字尾附加上「??」並不會顯示出原始碼,通常這是因為你查詢的物件並不是使用 Python 實作的,而是 C 或是其他具編譯功能的語言所建立的。
此種情況下,「??」字尾的輸出結果會和「?」字尾是一樣的。你會發現,特別是那些 Python 內建物件和型態,例如前面例子中使用的 len:

「?」以及「??」提供了一個快速的介面,讓我們可以找到任一 Python 函式或模組實際執行內容的相關資訊。
使用 Tab 補齊功能來探索模組
IPython 的另外一個好用的介面是 Tab 鍵自動補齊以及探索物件、模組、和名稱空間的功能。在接下來的例子中,將使用 <TAB>代表當 Tab 鍵被按下去的情況。
物件內容的 Tab 補齊
每一個 Python 物件都有許多的屬性和方法。就像之前說明過的 help 函式, Python 有一個內建的 dir 函式可以把這些屬性和方法都列出來,但是 Tab 自動補齊功能更好用,例如,想要瀏覽物件的所有可用屬性,可以在鍵入物件的名稱之後加上一個「 . 」句點符號,然後按下「Tab」按鍵。
只要輸入一個或多個字元,這個列表內容就會減少一些,此時再按下「TAB」按鍵就可以找到更符合的屬性或方法。
如果只剩一個符合的項目,按下「TAB」鍵就會直接把整列顯示出來。例如,以下的例子就會直接由 L.count取代。
雖然 Python 並沒有嚴格強制區分外部公有的和內部私有的屬性,但慣例上會使用底線符號來標明私有的內部屬性。為了避免混淆,這些私有的屬性和特殊的方法預設上在顯示時會被忽略,但是仍然可以透過加上底線的方式把它們顯示出來。
為了簡明一些,在這裡只列出實際輸出內容的前幾行。這些大部份都是 Python 的雙底線方法函式 (通常暱稱為「dunder」方法)。
在匯入套件的 Tab 補齊
Tab 補齊在匯入套件時也非常好用,例如,可以使用這個功能來找到 itertools 這個套件引入內容中,所有以 「co」開頭的方法:
In [10]: from itertools import co<TAB>
combinations compress
combinations_with_replaceent count
同樣的,也可以使用 TAB 補齊功能來檢視在你的系統中,可以匯入的套件有那些 (此功能和使用那一種第三方腳本,以及目前 Python 執行階段的能見度有關):
In [10]: import <TAB>
Display all 399 possibilities? (y or n)
Crypto dis py_compile
Cython distutils pyclbr
........... ............ ..........
diff lib pwd zmq
In [10]: import h<TAB>
hash lib mac http
heaps html hus1
(請留意,為了簡明顯示起見,在此不可能列出在我的系統中,所有 399 個可匯入的套件或模組。)
比 Tab 補齊更厲害的:萬用字元配對
在知道想要尋找的對象其開頭的幾個字元時,使用 Tab 補齊就非常方便,但是如果已知的字元是在函式或模組名稱的中間或是後面的話,這就派不上用場了。此時,IPython 提供的萬用字元「 * 」就可以用在這種情形上。
舉例來說,我們可以使用萬用字元來列出命令空間,所有以 「Warning」結尾的物件:

要留意的是 ,「 * 」可以符合任何的字串,也包括空字串。
同樣的,假設要找的是在名稱中的某處,包含某些字元的字串方法,可以使用以下方式:

在 IPython Shell 中的快速鍵
只要你花了一些時間在使用電腦,就會發現一些快捷鍵在工作流程中的用法。常用的像是 Cmd-C 和 Cmd-V (或是 Ctrl+C 和 Ctrl+V) 用來複製和貼上,就被廣泛的使用各式各樣的程式和系統中。老手們通常會更進一步:一些受歡迎的文字編輯器像是 Emacs、Vim 還有其他之類的,更是提供使用者各種複雜的快捷組合鍵。
IPython shell 沒有這麼誇張,但也提供了不少快捷鍵讓你在輸入指令時可以更快一些,這些快捷鍵其實不是 IPython 本提供的,而是透過相依的 GNU Readline 程式庫:因此,接下來有些列印的快速鍵可能會因為系統的配置而和你的有所不同。此外,這裡面有一些是運作在瀏覽器中的 notebook,這一節主要介紹的是在 IPython shell 使用的快捷鍵。
一旦你習慣使用快捷鍵,它們可以讓你快速的執行許多命令,你的手甚至可以不用離開鍵盤。如果你是 Emacs 的使用者,或是熟悉 Linux 型式的終端機操作,接下來的內容你將會非常熟悉。以下把這些快捷鍵分成幾組加以說明:導覽用快捷鍵、文字輸入快捷鍵、歷史命令快捷鍵以及雜項快捷鍵。
導覽用快速鍵
使用左方向鍵和右方向鍵在同一列中向前、向後移動非常直覺,但還是有其他的方法可以讓你的手不用離開你原先放的地方,而達到同樣的功能:
按鍵 動作
_________________________________________
Ctrl-a 把游標移至本列的最開頭位置
Ctrl-e 把游標移至本列的最末尾位置
Ctrl-b (或是左方向鍵) 把游標後退 (向左) 一個字元
Ctrl-f (或是右方向鍵) 把游標前進 (向右) 一個字元
文字輸入快捷鍵
大家習慣使用倒退鍵來刪除前一個字元,但手指頭還是要多移動一些距離才會到達這個按鍵,且它一次只能刪除一個字元。 在 IPython,有許多快捷鍵可以指定刪除輸入的文字內容的某些部份,其中最有用的就是一次刪除整列文字的快捷鍵。你很快會習慣使用 Ctrl-b 和 Ctrl-d 來取代原本你使用的倒退鍵刪除字元。
按鍵 動作
_________________________________________
倒退鍵 刪除本列的前一個字元
Ctrl-d 刪除本列的下一個字元
Ctrl-k 把從游標所在位置到本列末尾的所有文字剪下來
Ctrl-u 把從游標所在位置到本列開頭的所有文字剪下來
Ctrl-y 把之前剪下的內容貼上
Ctrl-t 交換前面2個字元
歷史命令快捷鍵
也許最好用的,應該是在這裡要說明的,用來操作在 IPython 中輸入過的歷史命令。在 IPython 使用的命令列歷史資訊可以跨越不同的操作階段,因為它把曾經輸入過的命令都儲存在 IPython profile 目錄的 SQLite 資料庫裡頭。最直覺的方式就是使用上、下方向鍵在這個歷史命令區中找出想要使用的命令,當然也有其他的選擇:
按鍵 動作
_________________________________________
Ctrl-p (或上方向鍵) 往前取得一個曾經輸入過的命令
Ctrl-n (或下方向鍵) 往後取得一個曾經輸入過的命令
Ctrl 反向搜尋曾經輸入過的歷史命令
反向搜尋特別有用。回想在人一節中,我們定義一個叫做 square 的函式,請從一個新的 IPython shell 執行階段透過反向搜尋再一次找出這個定義。當按下 Ctrl-r 時,可以看到如下所示的提示:
In [1]:
(reverse-i-search)'':
在此時如果開始輸入一些字元, IPython 將會自動以最近使用過的命令填入,然後顯示出符合那些字元的歷史命令:
In [1]:
(reverse-i-search)'sqa' ' : square??
在任何時候都可以輸入更多字元改善搜尋的結果,或是再次按下「 Ctrl-r 」更進一步搜尋其他符合的歷史命令。延續前面的操作,再按二下「 Ctrl-r 」,則會出現如下所示的樣子:
In [1]:
(reverse-i-search)'sqa': def square(a):
"""Return the square of a"""
return a ** 2
一旦找到想要的命令,接下 Return (或是 Enter) 就是可以終止此次的搜尋。接著使用這個找到的命令,繼續往下操作:
In [1]: def square(a):
"""Return the square of a"""
return a ** 2
In [2]: square(2)
Out [2]: 4
你也可以使用 「Ctrl-p / Ctrl-r 」或是上、下方向鍵在歷史命令中搜尋那些符合開頭字元的歷史命令,也就是說,如果輸入 「 def 」然後按下 「 Ctrl-p 」,就只會找到那些曾經輸入過,而且是以 「 def 」開頭的命令。
雜項快捷鍵
最後,一些不好歸類在上述的分類中,但也是很有用的快捷鍵如下:
按鍵 動作
_________________________________________
Ctrl-l 清除終端機畫面
Ctrl-c 中斷目前的 Python 命令
Ctrl-d 結束離開 IPython
「 Ctrl-c 」快捷鍵特別是在不小心執行了一個要運算很久的工作時非常有用。
IPython 的 Magic 命令
在前二節中展示了 IPython 能夠讓我們更有效的以互動的方式使用與探索 Python。在此將開始探討一些 IPython 架構在 Python 之上加強的語法。
IPython 在標準的 Python 語法之上加了一些命令,這些以 「 % 」字元開頭的,就是大家所熟悉的 magic command (神奇命令,或魔術命令)。這些 magic 命令被設計用來更簡潔的解決在標準資料分析時常見的一些問題。 magic 命令主要分成兩種型式:以 「 % 」開頭,用來操作單行輸入的 line magic,以及以 「 % 」開頭,用來操作多行輸入的 cell magic 。在此將會展示和討論一些簡要的例子。
貼上程式碼區塊:%paste 和 %cpaste
當在使用 IPython 解譯器時,當貼上多行的程式區塊時,經常會遇到一些預期之外的錯誤,尤其是其中含有縮排和解譯器記號的時候。一個常見的例子是,當你從網頁中找到一些範例程式,而想要把它們貼到解譯器裡面時。請看以下這個簡單函式:
>>> def donothing (x):
..... return x
這段程式被格式化成可以放在 Python 的解譯器中,但是如果你把它們直接貼到 IPython 中,則會出現以下的錯誤:
In [2]: >>> def donothing (x):
....: ..... return x
....:
File "<ipython-input-20-5a66c8964687>", line 2
... return x
^
SyntaxError: invalid syntax
直接貼上時,解譯器對於那些命令提示字元感到困惑,但別擔心,IPython 的 「 %paste 」magic 命令就被設計用來處理這種型式的多行程式碼輸入:
In [3]: %paste
>>> def donothing(x)
..... return x
### -- End pasted text --
「 %paste 」命令兼輸入和執行程式碼,所以現在這個函式已經準備好可以被呼叫使用了:
In [4]: donothing(10)
out [4]: 10
類似的命令是 「 %paste 」,它並不直接貼上,而是開啟一個交談式的多行輸入介面讓的們可以自行貼上一行或是多行指令片段,並批次執行之:
In [5]: %paste
Pasting code; enter '--' alone on the line to stop or use Ctrl-D.
:>>> def donothing(x)
:...... return x
:--
這些 magic 命令,包括接下來會看到的,讓一些在 Python 標準直譯器中做不到的功能可以在 IPython 中實現。
執行外部程式碼:%run
當開始撰寫更多程式碼時,你會想要同時可以在 IPython 中以互動的方式探索程式,以及使用編輯器來儲存,可以重複使用的程式碼。與其開啟另外一個新視窗來執行外部程式碼,在同一個 IPython 階段中執行的這些程式碼更方便,使用「 %run 」命令就可以做到這一點。舉個例子,假設建立了一個 myscript.py 檔案,其內容如下:

可以透過以下的方式在 IPython 中執行:
In [6]:%run mysciprt.py
1 square is 1
2 square is 4
3 square is 9
在執行了這段程式之後,其中定義的函式現在於 IPython 階段中已是可用的了:
In [7]:square(5)
Out [7]: 25
在 IPython 直譯器中使用「 %run 」執行程式有幾個可以調校如何執行程式碼的選項,可藉由鍵入 %run 以取得說明文件。
計算程式碼執行時間: %timeit
另外一個有用的 magic 命令是 「 %timeit 」,這是用來自動化測量緊隨在後的那個單行 Python 敘述執行時間的命令。例如,如果想要檢查 list comprehension 的效能:

%timeit 的優點是它可以針對簡短的命令,自動化的執行許多次以求出更令人信服的結果。對於多行的敘述,再加上一個「 % 」符號就可以改成為處理 cell 的命令,用來處理多行的輸入。例如,以下是使用 for 迴圈的一個等效串列建構式:

馬上可以看出,在這個例子中,使用 list compregension 比使用 for 迴圈建構串列還要快上 10%。
Magic 函式的求助:?、 %magic,以及 %lsmagic
就像是其他一般的 Python 函式,IPython 的 magic 函式也有 docstring,這份好用的說明文件可以透過標準的方式來取得,例如,要讓取 %timeit magic 命令的說明文件,只要簡單的輸入:

其他函式說明文件,也是使用相同的方式,而要取得對於 magic 函式的一般性介紹,包括一些使用範例,可以輸入如下:

要很快的顯示出所有,可以使用的 magic 函式清單,只要輸入如下:

最後,還是要提到,有需要的話,你也是可以使用相當直覺的方式定義,一個自己的 magic 函式。
輸入和輸出的歷程
之前提到過,在 IPython shell 中可以使用上方向鍵,以及下方向鍵,或是使用 Ctrl-p / Ctrl-n 快捷鍵找出之前輸入過的命令。更進一步的,包括在 shell 以及 notebook,IPython 有許多方式可以取得之前輸入過的命令所產生之輸出,包括這些命令本身的字串版本,接著來探討這個部份。
IPython 的 In 和 Out 物件
行文到此,相信你已經相當熟悉在 IPython 中使用 In [1]:/out [1]: 此種型式的提示字元。但是,這些其實不只是為了好看而已,它們提供了一些線索,讓我們可以在目前的執行階段中,存取之前的輸入和輸出。假設開始了一個執行階段,看起來像是以下這個樣子:

上述程式碼匯入了 math 套件,然後計算數字 2 的 SIN 和 COS。這些輸入和輸出都被顯示在 shell 中,並標上 In/Out 標籤,但不只如此,事實上,IPython 建立了一些名為 In 和 Out 的 Python 變數,並自動更新以反映,這些歷程資訊:

In 物件是一個串列,它依序保存了所有輸入的內容 (串列中的第一個項目,就是一開始的地方,因此 In [1] 就是第一個命令):

Out 並不是一個串列,而是一個字典,它由輸出竹所對應到的輸入編號做為索引:

並不是所有的操作都會有輸出:例如,import 敘述和 print 敘述並不會影響輸出。也許你會好奇為什麼 print 不會有輸出,如果把它看成是一個函式的話就可以理解,因為此函式的傳回值是 None ,為了精簡起見,所有回傳值是 None 的命令並不會被加到 Out 中。
此時,當需要和之前的執行結果交互使用時非常好用。例如,要使用之前 sin(2) ** 2 和 cos(2) ** 2 的執行結果來進行加總,如下:
In [8]: Out[2] ** 2 + Out[3] ** 2
Out [8]: 1.0
如預期的,三角恆等式的結果為 1.0 。在這個例子中使用之前的結果,也許並不是那麼必要,但是如果你之前執行過一個非常佔計算時間的結果,就會非常需要重用該結果以避免,重新再花大量時間去執行它。
底線快捷符號和先前的輸出
標準的 Python shell 只包含一個簡單的快捷符號用來處理之前的輸出:這個變數 「 _ 」(也就是一個單一的底線) 用來一直保持著,最近的一之輸出,而是這個功能在 IPython 也可以使用:
In [9]: print(_)
1.0
但 IPython 更進一步,可以使用雙底線,去取得兩次之前的輸出,三個底線符號,則可以再往前一步 (會跳過所有沒有輸出的命令):
In [10]: print(_)
-0.4161468365471424
In [11]: print(_)
0.9092974268256817
IPython 就停留在三個底線符號,因為再多就不好數了,而且超過3個之前的結果,使用行號來取得輸出,還比較容易。
還有一個快捷符號,也是要提一下,那就是把標準的 Out[X] 改為 _X (也就是一個底線再加上一個代表行號的數字):
In [12]: Out[2]
Out [12]: 0.9092974268256817
In [13]: _2
Out [13]: 0.9092974268256817
抑制輸出
有時候你希望讓敘述不要輸出。或是有時候執行的結果不想要放在輸出的歷程中,亦或是要讓它在別的參考被移除時可以解除配置。最簡單抑制命令之輸出的方法,是在該命令的行末處加上一個分號:
In [14]: math.sin(2) + match.cos上(2);
這個敘述會被安靜的計算,而結果不會被顯示在螢幕上,也不會被儲存在 out 這個字典變數中:
In [15]: 14 in out
Out [15]: False
相關的 Magic 命令
%history magic 命令可以用來批次存取之前用過的輸入。底下是一次列出前面 4 個輸入的方法:

就像之前一樣,可以輸入 %history? 取得更多的資訊以及可用的選項說明。其他類似的 magic 命令包括 %erun (可以用來重新執行歷史命令的某一部份)以及 %save (用來把某一群歷史命令存成檔案)。
IPython 和 Shell 命令
當以交談式使用標準的 Python 直譯器時,其中一個令人挫折的地方是,你會面對需要在多個視窗之間來回切換,以便執行 Python 工具和系統命令列工具的情況。IPython 彌補了這個缺口,它提供一些語法,可以直接在 IPython 的終端機中執行作業系統的 shell 命令。神奇的地方在於「驚嘆號」:所有放在「 ! 」之後的任何內容都不會在 Python 核心中執行,而是放到作業系統命令列上去執行。
接下來的操作環境,假設是在 Unix-like 作業系統中,像是 Linux 或是 Mac OS X 執行。其中一些操作示例在 Windows 作業系統下將會無法順利執行,因為 Windows 使用不同的 shell 型態 (然而隨著 Windows 下的原生 Bash 在 2016年發佈,很快的這將不會是問題!) 如果不熟悉作業系統 shell 命令操作,建議你可以複習一下由 Software Carpentry Foundation 所整理的 shell 教學 (http://swcarpentry.github.io/shell-novice/)。
Shell 的快速介紹
Shell 是一個文字的方式和電腦互動的方法。早在 1980年中期,當 Microsoft 和 Apple 推出,他們像現在一樣無所不在圖形式作業系統之後,大部份的電腦使用者和他們的作業系統互動的方式,就是使用滑鼠點按選單以及拖放移動的操作。但是作業系統在圖形使用者介面之前,就存在著使用文字輸入的基本控制方式:也就是在提示字元之後,使用者藉由輸入一個命令,然後電腦依照使用者教它的方式去運行。這些早期的提示字元系統,就是這些 shell 和終端機的前導者,也是現代資料科學家們現在還在使用的方式。
不熟悉 shell 的人也許會問,透過在圖示及選單上簡單的點按就可以完成許多結果時,為什麼還要這麼麻煩?Shell 的使用者也許會用另一個問題回答:透過輸入文字就可以完成這樣多工作時,為什麼還要用滑鼠去找圖示或選單來點按?這聽起來只是典型的在技術偏好上的抉擇,但是如果面對的工作沒那麼簡單時,就可以較清楚的看出,處進階工作時 shell 提供更多的控制,雖然它的學習曲線會讓一般電腦程度的使用者感到害怕。
舉例來說,這裡有一個 Linux / OS X shell 階段的例子,當使用者要在他的系統查詢、建立、以及修改目錄和檔案時 (osx:~ $ 是命令提示字元,所有在 $ 號後面是要輸入的命令;放在 # 後面的文字表示,這是一個註解的描述,並不是要輸入的內容):

# echo 就像是 Python 的 print 函式
# pwd = 印出工作的路徑 這就是我們所在的 「 path 」
# ls = 列出工作中目錄的內容
# cd = 變更目錄
這些動作都只是一些熟悉的操作之精簡方式 (瀏覽目錄結構、建立一個目錄、搬移一個檔案等等),它使用輸入文字取代透過滑鼠在圖示和選單之間的點按動作。只需要少數的命令 (pwd、ls、cd、mkdir、還有 cp ) 就可以進行大部份的檔案操作。當你從基礎再進一步往前時, shell 操作方法有時候,會更好用。
IPython 中的 shell 命令
你可以在 IPython 的 shell 環境中執行作業系統,任何命令提示字元接受的命令,只要在該指令前加上 「 ! 」就可以了。例如:ls、pwd、和 echo 這些命令,如下所示:

取出 / 傳入值到 shell
shell 命令並不只是可以從 IPython 中呼叫執行,也可以在 IPython 的名稱空間中和程式碼互動。例如,可以使用等號把任何 shell 命令中執行後的輸出放在 Python 的串列中:

傳回的值,並不是以標準竹戈串列型態回傳,面是由 IPython 所定義的一個特別的 shell 傳回值型態:

它的行為看起來像是 Python 串列,但是它具有更多的功能,像是可以使用 grep 和 fields 方法,以及 s、n、和 p 等屬性,讓我們更容易搜尋、過慮、和顯示這些結果。更多的相關資訊可以使用 IPython 內建的求助功能取得。
反過來,如果要傳遞 Python 的變數到命令列的執行環境中,可以透過 {varname} 語法:

大括號中的內容即為變數名稱,它會被 shell 命令列中的變數所取代。
和 Shell 相關的 Magic 命令
在使用 IPython 命令一段時間之後,你可能會注意到沒有辦法使月手 !cd 在檔案系統中切換:

這是因為在 notebook 中的 shell 命令是被執行在一個暫存的子 shell 中的關係。如果你打算永久的切換,目前的工作目錄,可以使用 %cd 這個 magic 命令:
實際上,在預設的情況下,其實可以不需要使用 % 符號:

這就是所謂的 automagic 函式,這樣的行為,可以透過 %automagic 這個函式來切換。
除了 %cd ,其他可以用的和 shell 相關的 magic 函式包括 %cat、%cp、%env、%man、%mkdir、%mv、%rm、以及 %rmdir,在 automagic 處於 on 的情況下,這些命令都是不需要加上 % 就可以使用的,這樣的功能,讓我們在 IPython 中操作時,就好像是在作業系統的命令提示字元 (終端機) 下一樣:

像是這樣對於 shell 指令的操作方式,就如同在終端機視窗一樣,就可以讓我們在撰寫程式碼時,減少在直譯器和 shell 命令之間來回切換的次數。
錯誤以及除錯
程式的開發以及資料的分析,總是需要許多反覆的測試。而 IPython 就提供了一些工具,讓這個過程更加順手。將會簡要的函蓋控制 Python 例外回報的一些選項,然後探索這些用來在程式碼中除錯的工具。
控制例外
當 Python 腳本執失敗時,通常都會產生一個例外。當直譯器遇到這些例外時,這些造成錯誤的相關資訊,會被放在 trackback 中,它可以在 Python 中加以存取。透過 %xmode 這個 magic 函式, IPython 允許控制。當例外產生時,要顯示資訊的數量。參考以下這段程式碼:

呼叫 func2 造成錯誤,而檢視列出來的追蹤資訊,讓我們可以明確的,看出發生了什麼事,在預設的情況下,這樣的追蹤包含了可以指向,導致這個錯誤的步驟之多行前後文內容。 %xmode magic 函式 (簡稱為例外模式) 用來改變列印資訊的模式。
%xmode 需要輸入一個參數,也就是模式設定,共有三種模式可用:Plain、Context,和 Verbose。預設是 Context,這個模式就是上面看起來的樣子,而 Plain 模式則較為精簡。呈現的資訊較少:
 1
1Verbose 模式加上了一些額外的資訊,包括任何被呼叫的函式所使用之參數:

這些額外的資訊可以協助我們更明確的暸解,發生這個例外的原因。所以,為何不全部使用 Verbose 模式? 因為當程式碼很複雜時,這樣的回溯會變得非常長。依照不同的內文而定,有時候預設的簡要模式會比較容易使用。
在檢視回溯訊息不夠用時的除錯方法
Python 標準的互動式除錯是 pdb。它讓使用者可以進入程式碼,逐列去理解不易發現的引發錯誤之原因,而 IPython 的加強版是 ipdb,也就是 IPython 的除錯器。
在 IPython 中,最方便的除錯介面是 %debug magic 命令。在遇到例外之後呼叫它,它會自動的開啟一個交談式的介面並提示出現例外的點。 ipdb 提票字元讓我們可以探索目前堆疊中的狀態,查看可用變數,甚至執行 Python 的命令。
來看看最近遇到的例外,然後做些基本的工作 (列印出 a 和 b 的值),之後輸入 quit 離開除錯階段:

然而,這個交談式的除錯器,允許我們做更多的事,甚至可以在記憶體堆疊中上下探查,並查詢其中變數的值:

這樣可以快速的找出不只是引發錯誤的地方,也可以知道是那些函式的呼叫,引發了這次的錯誤。
如果想要讓除錯器,在發生例外時自動的執行,可以使用 %pdb magic 函式去開啟,這樣的自動行為:

最後,如果打算讓一後程式碼,從頭到尾都是以互動的方式執行,可以使用 %run -d ,接著使用 next 命令一步一步的執行,每一行程式碼。
除錯命令的部份列表
交談式的除錯介面中,還有許多命令可以使用,在此只列出其中的一部份。底下表格中所列的是一些常用的命令,以及其說明:
命令 說明
_________________________________________
list 顯示在檔案中目前的位置
h(elp) 顯示所有命令的列表,或是針對指定的命令提供求助訊息
q(uit) 離開除錯器及程式
c(ontinue) 離開除錯器,但是程式還是繼續執行
n(ext) 前往程式的下一步
<enter> 重複前一個命令
p(rint) 印出變數
s(tep) 進入副程式中
r(eturn) 離開程式
剖析和測定程式碼的時間
在開發程式的過程,以及建立資料處理管線 (popeline) 時,經常有一些需要在不同的實作方式間取捨的情況。過早在開發,你的演算法時關心這個問題,可能會適得其反。就像是 Donald Knuth 說的「 在百分之九十七的時間裡,我們應該要忘記,那些小的效能問題。太早優化是萬惡之源 」。
但是當程式碼已經可以運作時,更進一步的去挖掘,它的效能就很有用了。有時候探查一個命令或是一組命令的執行時間很有用處,其他時候,深入挖掘多行的處理程序,然後判定在一些複雜的一系列操作中,那裡是瓶頸也很有用。 IPython 提供了各式各樣的功能,用來操作,這一類型的剖析和測時。在此時將要推論以下的 IPython magic 命令:
%time 單一行敘述的執行時間
%timeit 重複執行單一行敘述以取得更正確的時間
%prun 使用剖析器執行程式碼
%lprun 使用逐行執行剖析器執行往式碼
%memit 測量單一行敘述的記憶體使用量
%mprun 使用逐行執行記憶體剖析器執行程式碼
後面4個命令,並不在 IPython 的預裝套件中,需要安裝 line_profiler 和 memory_profiler 延伸套件才行。
程式碼片段的測時:%timeit 和 %time
在 「 IPython 的 Magic 命令 」中曾看到過 %timeit line magic 和 %%timeit cell magic 被用來測量重複執行的程式碼片段之時間:

因為此運算執行的非常快,所以 %timeit 自動做了非常大量的重複運算。對於那些執行較慢的命令, %timeit 會自動調整,使用較少的重複次數:

有時候重複運算,並不是最好的選項。例如,當排序一個串列時,可能會被重複的運算所誤導。對有序串列的排序速度,比對末排序的串列進行排序的速度要來得快,因此重複這些運算會造成測時上的誤差:

像這種情形,%time 可能會是比較好的選擇,對於需要長時間執行的命令也是,此種命令較不會受到一些短的系統相關延遲所影響。以下是比較對於已排過序以及末排過序的串列,進行排序運算的時間長度:

請留意有序的串列排序運算快了多少,以及使用 %time 測到的時間比使用 %timeit 測到的時間多了多少,就算是對有序的串列也一樣,事實上,%timeit 在私底下做了一些聰明的事,以防止系統呼叫妨礙計時工作。例如,它預防了系統對末使用的 Python 物件進行清除的工作 (也就是記憶體垃圾回收),這有可能會影響到計時。也因為這個原因,%timeit 的結果通常會明顯的比 %time 還好。
使用 %% 的 cell magic 語法可以讓 %time 像 %timeit 一樣,對多行的程式碼,進行測量時間的工作:

更多關於 %time 和 %%timeit 的資訊,以及可用的選項,請使用 IPython 的求助功能 (也就是在 IPython 的提示字元後輸入 %time?)
剖析整個程式: %prun
一個程式是由許多單行的敘述所構成,有時候在前後文中去量測時間,會比只量測個別的敘述來得重要。 Python 有內建程式碼剖析器 (請參考 Pytho 的說明文件),但 IPython 提供一個更方便的方法,使用這個剖析器,就是利用 %prun 這個 magic 函式。
舉例來說,以下定義了一個進行一些計算的簡單函式:

現在以 %prun 帶著一個函式呼叫來看看剖析後看結果:

在 notebook 中輸出被顯示成像是下面這樣的頁面調度程序:

結果之表格以,每一個函式呼叫的總時間排序列表,花越多時間的放在越上面。在此例中,最多的執行時間是在 sum_of_lists 中的列表式推導 (list comprehension)。從此點,我們可以開始思考,要改進演算法的效能時,需要做什麼樣的改變。
使用 %lprun 逐行剖析
使用 %lprun 以函式為單位來剖析程式很有用,但有時候如果能有逐行的剖析報告會更加的方便。這個功能並沒有內建在 Python 和 IPython 中,需要安裝 line_profiler 套件才行。安裝 line_profiler 這個套件,只要使用 Python 的套件管理器 pip 就可以了:
$ pip install line_profiler
接下來,使用 IPython 載入 line_profiler 提供給 IPython 的延伸模組:

現在,%lprun 命令將可以對任何一個函式執行逐行剖析。在此例中,需要明確的指定要剖析的是那一個函式:

和之前一樣,此 notebook 會發送,這個結果到頁面調度程序,看起來會像是下面這個樣子:

最頂端的這些資訊,透露出閱讀這些結果的關鍵:計時的時間,以微秒為單位,從這裡可以看出程式中,那裡花掉了最多的時間。根據此點,可以利用這些資訊去修改程式,讓它在需求的使用情境下,得到更好的執行效能。
剖析記憶體的使用:%memit 和 %mprun
另一個面向的剖析是在運作時,記憶體使用的總量,這可以使用,另外一個 IPython 的延伸套件:memory_profiler 做到。就像是 line_profiler,也是使用 pip 來安裝,這個延伸套件:
pip install memory_profiler
然後在 IPython 中載入這個延伸模組:

此記憶體剖析延伸模組,包含了2個有用的 magic 函數:%memit magic (提供風同於 %timeit 的記憶體量測) 以及 %mprun 函式 (等同於 %lprun 的記憶體量測)。 %memit 函式使用起來相對簡單:

由上可以看出,這個函式大約使用了 100 MB的記憶體。
對於逐行列出記憶體的使用,可以使用 %mprun magic 。不幸的是,這個的指令,只能使用在分開定義的外部模組,不能使用在 notebook 裡面的。所以,接下來我們要透過 %%file magic 建立一個簡單的模組叫做 mprun_demo.py,在裡面放入加了一點改變的sum_of_lists 函式,讓記憶體的剖析結果,可以更清晰一些:

現在可以匯入這個新版本的函式,然後透過記憶體逐行剖析器來執竹:

結果也是以頁面調度器的方式呈現,提供了此函式記憶體的使用情形,看起來像是以下這個樣子:

其中在 Increment 欄位可以看出,每一行所影響的總記憶體有多少:可以觀察當建立和刪除串列 L 時,多使用了25 MB 的記憶體,這是送在 Python 直譯器本身的背景記憶體用之上的。


留言
張貼留言